Predicción del número de socios en un centro deportivo durante la pandemia
sábado 15 de mayo de 2021 - 17:08 GMT+0000
Trabajo de fin de Máster
-

 Predicción de la demanda en un centro deportivo durante la pandemia de COVID-19Máster Universitario en Ciberseguridad e Inteligencia de Datos
Predicción de la demanda en un centro deportivo durante la pandemia de COVID-19Máster Universitario en Ciberseguridad e Inteligencia de Datos
Introducción
El tratamiento de datos es un proceso clave en los negocios para poder tomar decisiones mejores informadas. En particular, el uso de datos históricos para crear modelos predictivos permite a las empresas tomar decisiones adelantándose a los acontecimientos. En un tiempo especialmente incierto debido al impacto de la COVID-19, poder realizar estimaciones de lo que va a suceder, toma una importancia adicional para ayudar a la toma de decisiones que permita la continuidad de la empresa.
Este trabajo de fin de máster recoge este tratamiento y modelado de datos para predecir la evolución del número de socios en Radazul Sport Center, un centro deportivo situado en la isla de Tenerife.
Contexto
Este trabajo de fin de máster recoge la última parte de un extenso proyecto de auditoría de datos a este centro deportivo por un equipo de esta cátedra formado por Carlos Alberto González, Ginés León, Erika Herrera, Samuel Tarife y el autor de este TFM (Carlos Domínguez). De manera resumida, en este proyecto:
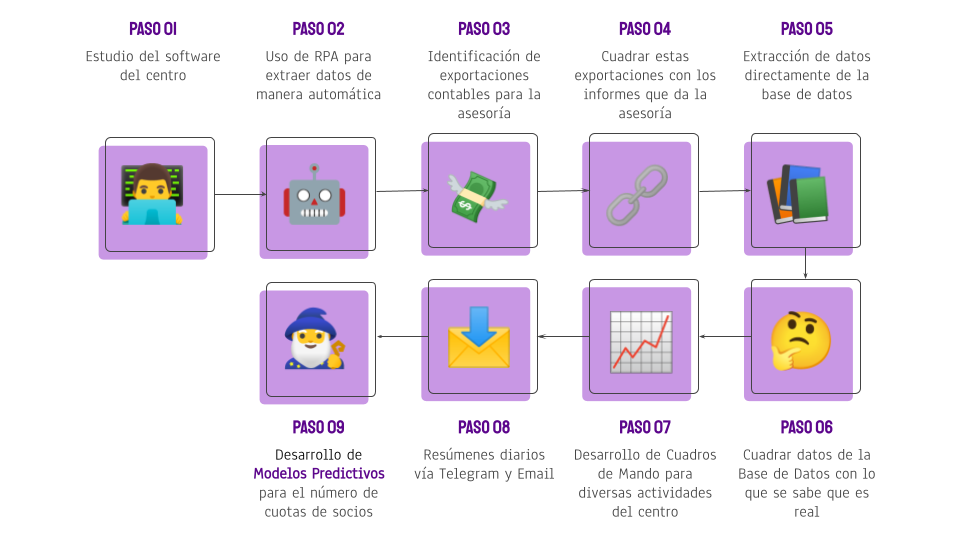
- Guiados por el Mapa BOB, se realizó un estudio de lo que se podría hacer en el centro basado en el uso de datos. Y se empezó investigando el software que usa el centro para registrar su actividad.
- Se implementó una solución basada en Robotic Process Automation (RPA) para la extracción automática de los datos a través de la interfaz gráfica del software.
- Se identificaron unas exportaciones periódicas de datos contables del software que se envían a una asesoría.
- Se realizaron cuadros de mando comparando la información exportada del software con la información que da la asesoría para asegurarse que cuadran los datos y que la empresa pueda tener un control propio de esta información.
- Se identificó y se pudo acceder a la base de datos del software, por lo que a partir de este momento pudo empezar a extraer la información del software en cualquier momento, de manera que el control que se le puede ofrecer a la empresa de su actividad esté siempre actualizado.
- Se realizaron cuadros de mando comparando la información que ya se tenía con la extraída de la base de datos para asegurarse de que son correctos.
- Además, en este momento se tenía acceso a una gran variedad de datos del centro, por lo que se pudieron realizar cuadros de mando de diversas materias útiles para la toma de decisiones y sugerir mejoras en los procesos de la empresa para que tenga un mejor control de su actividad.
- Se desarrolló un sistema para enviar resúmenes diarios por Email de las actividades de interés.
- Finalmente, como parte de este TFM, se desarrollaron modelos predictivos para la evolución de la demanda de cuotas de socios del centro.
Resumen del proyecto
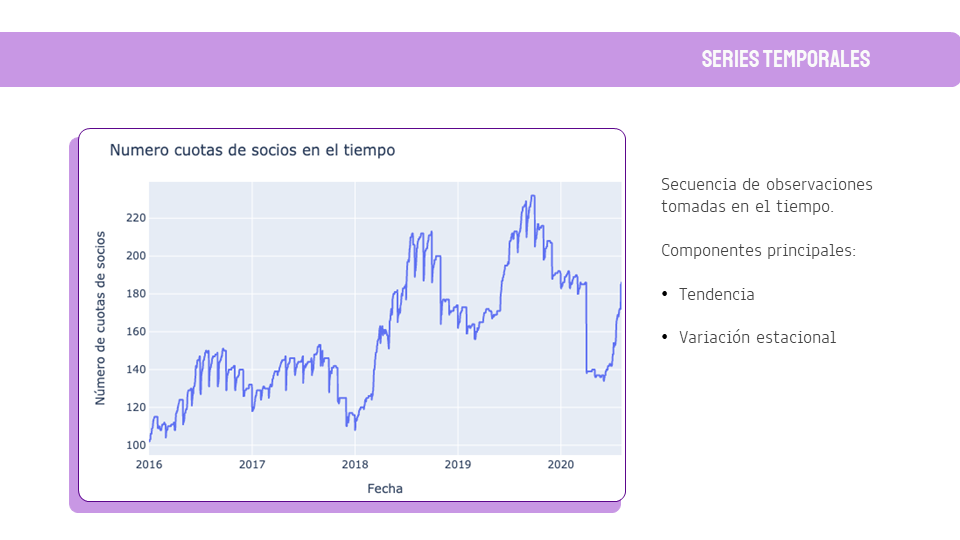
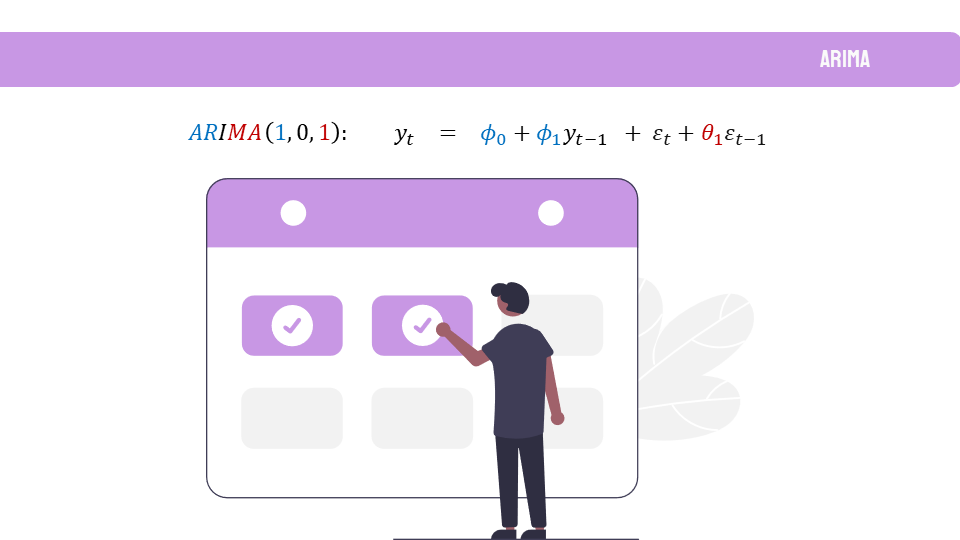
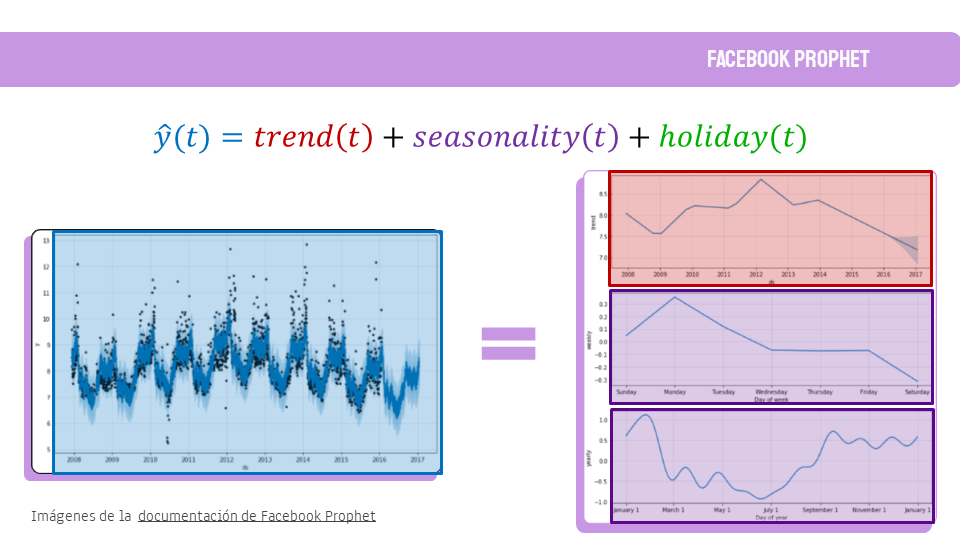
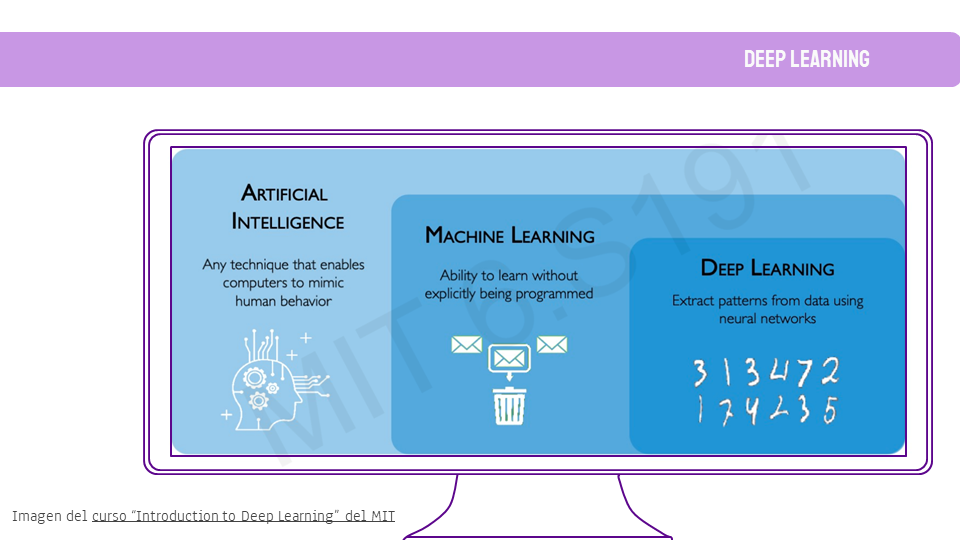
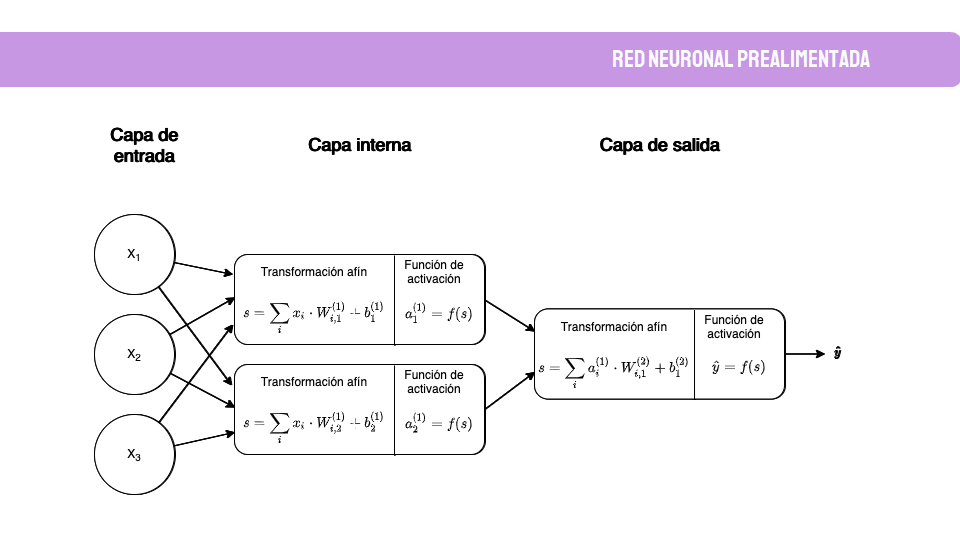
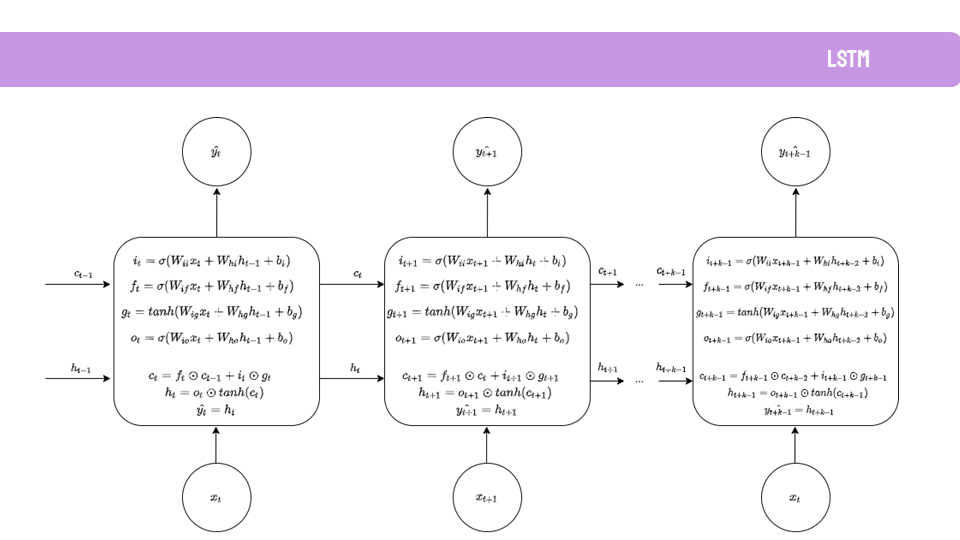
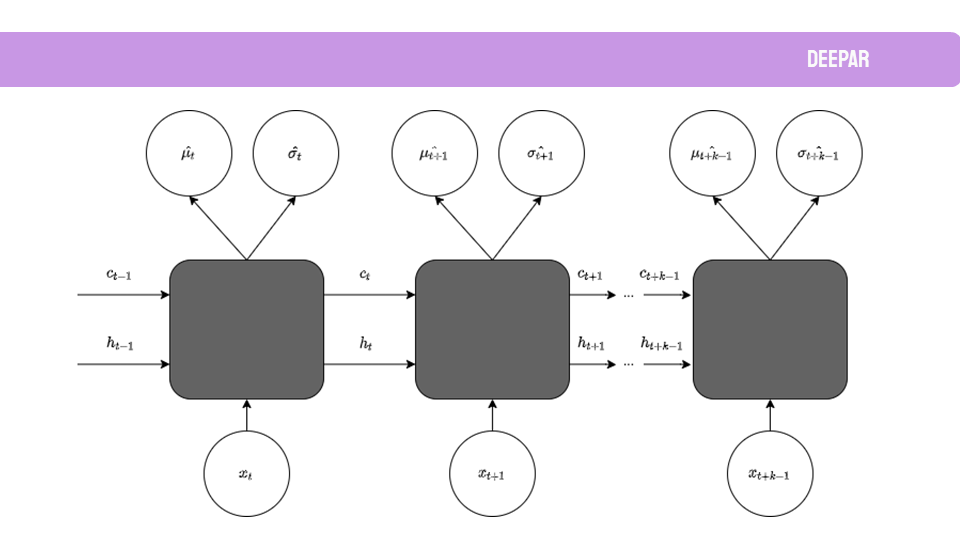
Como el dato a predecir es el número de nuevos socios en el tiempo, la primera parte de este TFM incluye los fundamentos teóricos de este tipo de dato: series temporales. Esto incluye también la teoría de los modelos predictivos que se han usado, desde modelos estadísticos como ARIMA o SARIMAX, hasta modelos de Deep Learning como Redes Neuronales Recurrente o DeepAR.
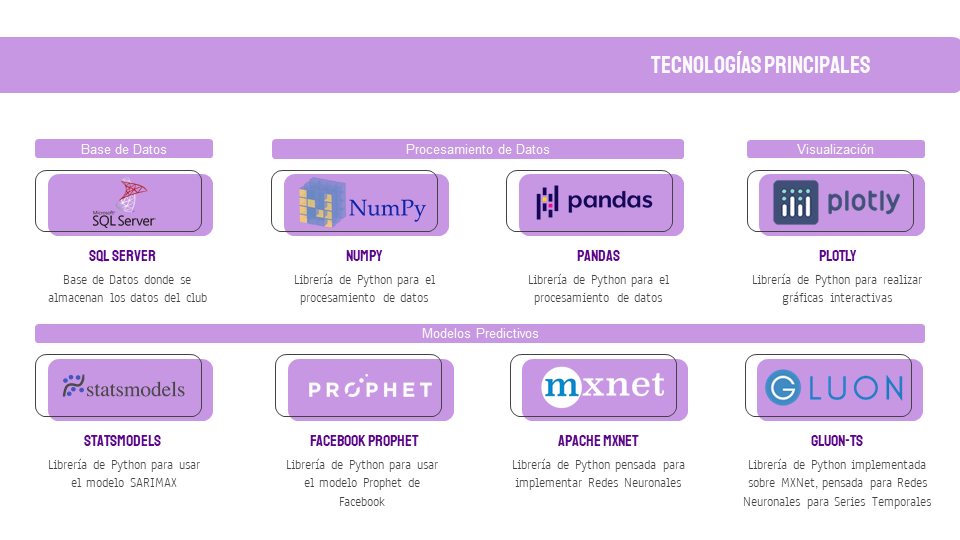
Tras esto, se muestra una breve descripción de las herramientas utilizadas: SQL Server como base de datos, Python como lenguaje de programación, las librerías MXNet y GluonTS para los modelos de Deep Learning para series temporales, etc.
A continuación, se describen los procesos aplicados para el tratamiento de datos. Y se detallan las pruebas realizadas con los modelos predictivos, por una parte sin tener en cuenta el impacto de la COVID-19 para evaluar si los datos eran suficientemente buenos para continuar con el proyecto. Y en una segunda parte, se realizaron predicciones teniendo en cuenta el año 2020 para realizar predicciones hacia el futuro.
De estos modelos, SARIMAX dio unos resultados muy prometedores para datos mensuales. Sin embargo, es un modelo muy costoso computacionalmente para predecir datos con periodicidad diaria. Por ello también se probaron otros modelos, pero sin lograr unos resultados tan satisfactorios. En parte era de esperar ya que los modelos de Deep Learning funcionan mejor cuando tienen más de una serie temporal de la que extraer patrones. Por tanto, una posible línea futura para este proyecto es añadir otras series temporales como: el número de accesos al club en el tiempo, el número de reservas, el número de actividades, datos meteorológicos como precipitaciones o viento, datos de movilidad, etc.


Más información
La memoria del trabajo está disponible al público en el Repositorio Institucional de la Universidad de La Laguna.
- Autor: Carlos Domínguez García
- Tutor: José Marcos Moreno Vega
- Cotutora: María Belén Melián Batista