Aplicación práctica de los datos abiertos: actualización y predicción
lunes 26 de julio de 2021 - 12:43 GMT+0000
Trabajo de fin de Grado


Introducción
Cada vez es más común encontrarnos con portales de datos abiertos en internet. Con estos portales se pretende que los datos disponibles puedan hacerse públicos y accesibles tanto para la ciudadanía como para las empresas.
Sin embargo, existen portales de datos abiertos que no se actualizan periódicamente, o sus datos presentan errores de persistencia. Por esta razón, es de vital importancia saber analizar los datos de manera correcta para determinar la calidad de actualización de cada portal, y mejorar la visualización de los valores obtenidos de forma que sean entendibles por cualquier usuario.
De esta forma, se ha elaborado un semáforo para determinar, a tiempo real, la calidad del dato de la API meteorológica de GRAFCAN, ya que suele ser un conjunto de datos de gran interés. Este semáforo ofrece métricas de la fiabilidad de actualización del dato, permitiendo a empresas y usuarios usar la API con seguridad.
Por otro lado, en el estado actual de pandemia, el uso de los datos abiertos ha sido indispensable para numerosas empresas y ciudadanos, los cuales podían saber la incidencia acumulada de casos (entre otros datos de interés) que había en su zona en tiempo real. Debido a la importancia que ha tenido este dato en la sociedad actual, se ha decidido realizar predicciones sobre la incidencia acumulada de la COVID-19 en Tenerife, a partir de datos abiertos.
Contexto
El auge del Open Data en los últimos años ha sido extremo. En concreto, en España se disponía en el año 2013 de 5.000 conjuntos de datos disponibles en diferentes portales oficiales. En la actualidad, se poseen más de 45.000 datasets unificados en el mismo portal. Este desarrollo ha aumentado el uso de los datos públicos por parte de la ciudadanía, siendo más necesario que nunca realizar un seguimiento de la actualización de los portales para evitar problemas con los datos obtenidos.
El proyecto podía continuar investigando otros portales con una metodología similar. Sin embargo, tras realizar un análisis manual observamos que los datos de la COVID-19 se actualizan diariamente y presentan una fiabilidad muy elevada, por lo que no se requiere un semáforo tan elaborado como el realizado con GRAFCAN. En cambio, elaborar predicciones con estos datos de interés es un campo que se ha explorado en menor medida y puede tener más relevancia con este dataset en concreto.
Para entender el tema de las predicciones con datos de la COVID-19 se debe explicar lo que es una serie temporal. Esta se puede definir como una colección de observaciones de una variable recogidas secuencialmente en el tiempo. Poseen 4 características (componentes) que ayudan a interpretar su comportamiento y que se detallan en la Memoria. Las librerías empleadas con el objetivo de realizar las predicciones son Prophet y Neural Prophet.
Resumen del proyecto
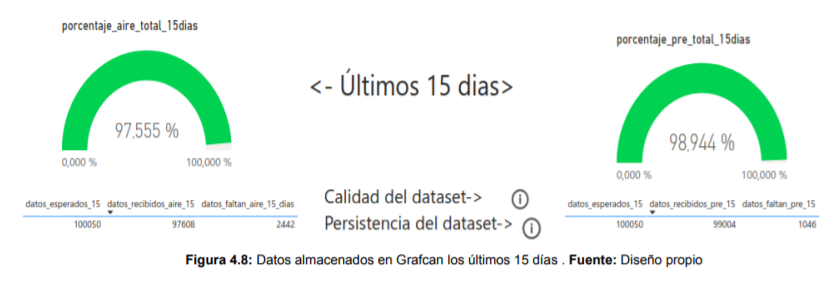
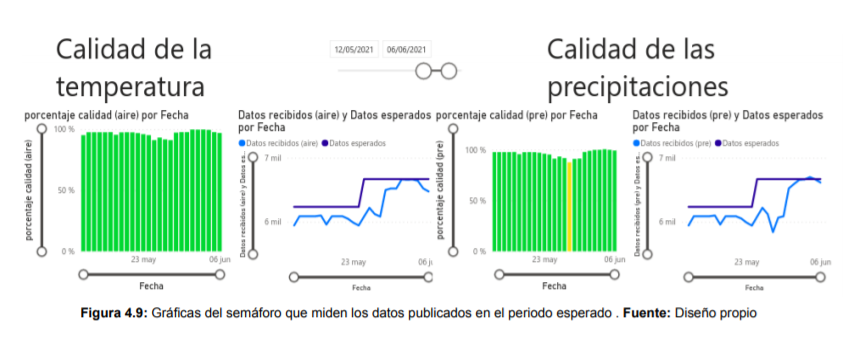
El proyecto se basa en el uso de los datos abiertos. Por un lado, para determinar la fiabilidad de actualización de la API de GRAFCAN se ha empleado el ‘Business Intelligence’, es decir, diferentes estrategias y herramientas para transformar información abstracta en conocimiento útil. En concreto, se han realizado 4 procesos ETL para la obtención y transformación de los datos en Python. Además, se ha realizado un cuadro de mando mediante la herramienta de Power BI, simulando un semáforo, que permite monitorizar a tiempo real los datos de actualización, siendo más entendible para el usuario.
Los resultados muestran el buen funcionamiento de la API. Se recoge que el conjunto de los datos obtenidos en su totalidad es muy elevado, que la calidad de obtención del dato en su primera publicación suele estar entre 92% y 97%, y que la persistencia es adecuada.
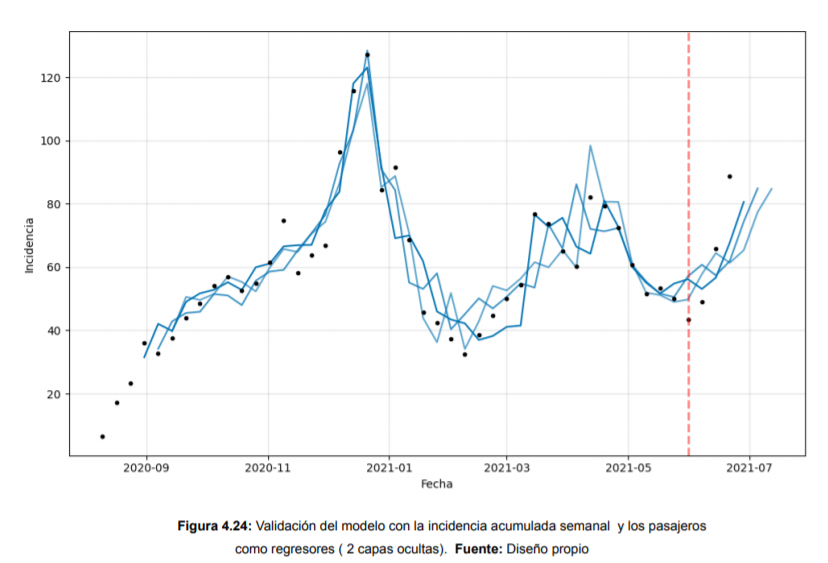
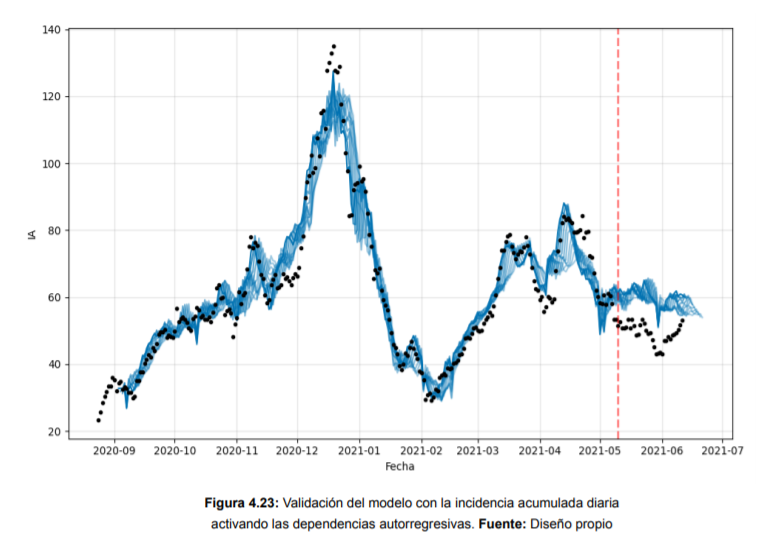
Por otro lado, en lo que respecta al dataset de la COVID-19, tras realizar un análisis de la información recopilada, se comenzaron a elaborar los modelos de predicción sobre la incidencia acumulada en la isla de Tenerife. Para ello, se ha utilizado en primera instancia Prophet, una librería de código abierto que se puede usar en Python y en R. Esta se caracteriza principalmente por la interpretabilidad de los hiperparámetros, modelando la tendencia, las variaciones estacionales, y los días festivos. En segunda instancia se ha utilizado Neural Prophet, librería basada en Pytorch que combina la interpretabilidad de Prophet con las redes neuronales. Además, a diferencia de Prophet permite añadir regresores rezagados, es decir, otras variables que ayuden a mejorar la predicción. Por esta razón, se han añadido como regresores los turistas procedentes de Gran Bretaña y Alemania con destino la isla de Tenerife, ya que pueden generar una variación en la curva de Incidencia Acumulada.
En este TFG, se comparan los resultados de ambos modelos, en igualdad de condiciones y con los mejores hiperparámetros obtenidos.
Más información
La memoria del trabajo está disponible al público en el Repositorio Institucional de la Universidad de La Laguna.
- Autor: Brian Samir Santamaría Valero
- Tutor: José Luis Roda García
- Cotutor: Ginés León Rodríguez