
Avda. Trinidad, Nº 61. Aulario Torre Profesor Agustín Arévalo. Planta 0.
C.P. 38071 San Cristóbal de La Laguna.
Tenerife.


La mayoría de las estaciones de servicio cuentan con depósitos de almacenamiento de combustible que están bajo tierra. Cuando se produce una fuga, el suelo circundante se contamina, provocando un daño medioambiental que puede llegar a ser grave. Hoy en día, las estaciones modernas incorporan diferentes mecanismos, más o menos sofisticados, para tratar de detectar lo antes posible las fugas en los depósitos de almacenamiento. Sin embargo, no es una práctica generalizada, por lo que para estaciones relativamente antiguas resulta de gran utilidad disponer de alguna forma de detectar las fugas de combustible lo antes posible.
La Inteligencia Artificial y, más concretamente, las técnicas de Aprendizaje Automático (Machine Learning), pueden emplearse para tratar de detectar lo antes posible las fugas de combustible en estaciones de servicio. Para ello se hace uso de la información del libro de inventario de la estación, que no es más que un registro en el que, con cierta periodicidad, típicamente una vez al día, se refleja la información relevante del funcionamiento de la estación. Estos datos son: el volumen del depósito de almacenamiento al comienzo del día, el volumen de ventas, el volumen de descargas procedentes de las cubas que llenan los depósitos, ciertos ajustes que se realizan, y el volumen al final del día. Aparentemente, con estos datos la detección de fugas debería ser un problema trivial. Si al volumen al comienzo del día se le suman las descargas, se le restan las ventas y se tienen en cuenta los ajustes, el volumen resultante debería coincidir, en ausencia de fugas, con el del final del día. Por tanto, si al hacer esta operación se observa que hay un déficit de litros en el depósito, se podría concluir que es debido a una fuga. Sin embargo, diversos factores como los cambios de volumen del combustible con la temperatura, la volatilización del mismo, los errores humanos a la hora de anotar la información en el libro de inventario, etc., lo convierten en un problema complejo.
Figura 1
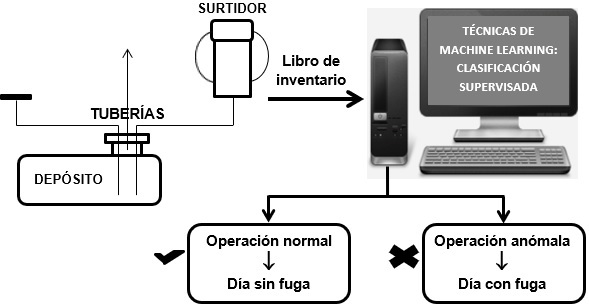
Aplicación de técnicas de Machine Learning para la detección de fugas de combustible en estaciones de servicio.
Además, para que un sistema de detección de fugas pueda ser aprobado para su implantación en una estación real debe ajustarse a la legislación vigente. La normativa europea UNE-EN 13160-5 (2017) establece que se debe detectar un caudal de fuga de 19.2 litros/día en un plazo máximo de 14 días con un error no superior al 5%, teniendo en cuenta que los errores pueden deberse tanto a falsos positivos (no hay fuga y el sistema de detección dice que sí) como a falsos negativos (hay una fuga y el sistema no la detecta).
Dentro de las técnicas de Machine Learning se distingue entre el aprendizaje supervisado y el no supervisado. En el aprendizaje supervisado se dispone de un conjunto de muestras etiquetadas, es decir, se sabe a priori a cuál de las clases pertenece cada una. En cambio, en el aprendizaje no supervisado se procesan datos sin etiquetar. A su vez, dentro de los algoritmos supervisados encontramos dos grandes categorías: los algoritmos de regresión, cuyo objetivo es predecir valores numéricos, y los algoritmos de clasificación, que tienen como misión predecir a qué clase pertenece un cierto conjunto de datos, es decir, asignar una clase a cada muestra. Teniendo todo esto en cuenta, para la detección de fugas de combustible en estaciones de servicio se propone el uso de clasificadores supervisados de dos clases, ya que se dispone de datos etiquetados que únicamente pueden pertenecer a la clase ‘fuga’ o a la clase ‘no fuga’. En el problema que nos ocupa, los datos o muestras son días de operación de la estación de servicio.
Para que los clasificadores sean capaces de determinar a qué categoría pertenecen las muestras deben ser debidamente entrenados con un conjunto de datos que sea lo suficientemente representativo de todas las clases, que en este caso son sólo dos: día con fuga y día sin fuga. Se debe tener en cuenta que normalmente los libros de inventario sólo reflejan situaciones de no fuga, por lo que los datos correspondientes a situaciones de fuga deben simularse siguiendo las indicaciones que para ello se establecen en la norma UNE-EN 13160-5 (2017), distinguiendo dos casos: fugas constantes y fugas variables. En el primero de ellos el caudal de combustible que se fuga es el mismo todos los días, mientras que en el segundo dicho caudal es proporcional al volumen de combustible en el depósito.
Una vez que los clasificadores han sido entrenados, se les somete a un proceso de validación en el que se les presentan muestras distintas de las del conjunto de entrenamiento y deben decidir a qué clase pertenece cada una. Además de la estructura interna del clasificador, que debe adecuarse bien a la naturaleza del problema concreto que se está considerando, uno de los factores que más influyen en la calidad de la clasificación es la elección de las características con las que trabajan los algoritmos. Dichas características deben aportar información útil para poder asignar a cada muestra la clase a la que pertenecen. En el problema de la detección de fugas de combustible la característica que mejor permite discriminar entre clases es la variación, que se calcula como la diferencia entre el volumen teórico y el volumen real del depósito de almacenamiento. Por tanto, a partir de la información del libro de inventario es inmediato obtener la característica variación para cada día de operación de la estación.
Tras haber realizado los experimentos oportunos, se concluye que las técnicas de Machine Learning y, en concreto, ciertos clasificadores supervisados de dos clases, permiten detectar fugas de combustible en estaciones de servicio, incluso en menos tiempo del establecido por la normativa, minimizando así el impacto medioambiental de dichas fugas.
AUTORA: Marta Sigut Saavedra
ILUSTRACIÓN CARLA GARRIDO
Archivado en: Revista Hipótesis
Etiquetas:,Número 15, Artículo, Ciencia y Sociedad, Universidad de La Laguna,

Avda. Trinidad, Nº 61. Aulario Torre Profesor Agustín Arévalo. Planta 0.
C.P. 38071 San Cristóbal de La Laguna.
Tenerife.